논문 개요
이 논문은 결정 트리(Decision Tree) 기법이 의료 데이터를 포함한 다양한 분야에서 사용됨을 소개하고 있습니다. 특히 분류(classification)와 예측(predicion) 의 관점에서 결정 트리의 장점과 실제 연구(MDD) 사례를 들어 설명을 하고 있습니다. 이 논문은 결정트리의 기본 구조와 개념, 모델을 만드는 과정을 쉽게 설명하고 이고, 몇개의 알고리즘(CART, C4.5)를 간단하게 소개하고 있습니다.
결정 트리?
결정 트리는 데이터를 일련의 조건들에 따라 분할하여 트리 형태로 시각화하는 모델을 말합니다.
각 가지(branch)는 조건에 따라 나뉘며, 말단 노드는 모델의 예측 또는 결과 를 나타냅니다.
루트 노드(시작점)에서 각 내부 노드를 거치면서 조건이 적용되어 최종적으로 하나의 말단 노드에 도달하게 됩니다.
이때 결정 트리의 장점들을 논문에서 소개하고있는데,
- 해석 용이성: 비전문가도 트리 구조를 보면 쉽게 파악 가능
- 결측값 처리 가능: 별도의 결측값 대체 없이도 모델 내에서 자동 분류 처리
- 비모수성: 변수의 분포 가정 없이 사용 가능
- 왜도(skewness), 이상치(outlier)에 간건함

결정 트리 모델의 주요 개념
- 노드의 구조
- 루트 노드(root node): 전체 데이터가 처음 시작되는 지점
- 내부 노드(internal node): 중간 조건을 적용하는 지점
- 리프 노드(leaf node): 최종 예측 또는 분류 결과를 가지는 지점
2. 가지(branch)
조건에 따라 분할된 경로로, 입력 변수의 상태에 따라 데이터를 하위 그룹으로 나눕니다
3.분할(splitting)
데이터를 입력 변수 기준으로 나누는 과정이며, 분할 기준으로는 정보 이득(informaion gain), 지기 지수(Gini index), 엔트로피(entropy) 등이 사용됩니다
4. 정지(stopping)
분할을 계속하게 될경우 overfitting 의 가능성이 존재하므로, node별 최소 샘플 수와 최대 깊이, 노드 순도 등을 사용하여 적절히 정지 시킵니다.
5. 가지치기(pruning)
stopping 으로는 결정트리에서 과적합을 방지하기 어려워 따로 불필요하게 깊어진 가지를 제거합니다.
이때 사전 가지치기(pre-pruning), 사후 가지치기(post-pruning)으로 나뉘는데 전자는 트리 생성 중 조건을 두어서 불필요한 분기를 미리 막는방법, 후자는 트리를 다 만들고 정보량이 적인 분기(관련성이 적은) 분기를 제거해 단순화 하는 방법을 의미합니다.
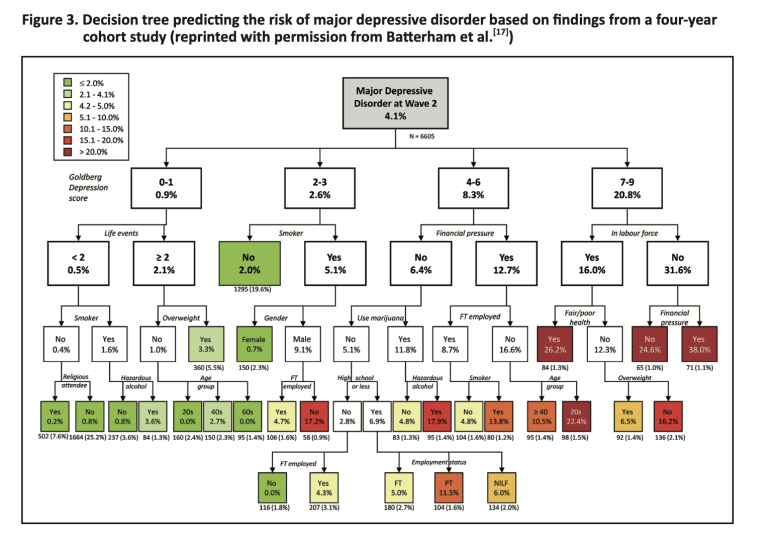
실제 의료 데이터 적용 예제: 우울 장애(MDD) 예측
논문에서는 실제 4년간 코호트의 연구 데이터를 바탕으로 우울장애에 걸릴 위험을 예측하는 결정 트리 모델을 구축합니다.
- 사용된 변수: 흡연 여부, 성별, 고용상태, Goldberg 우울증 점수
- 분석 결과(간략히):
- 비흡연자의 경우 MDD 발병률 : 2% (놀람)
- 남성 흡연자 중 Goldberg 점수 2~3점 + 풀타임 미취업자: 17.2 %
이처럼 다양한 변수들의 조합으로 질병 위험률을 구간별로 나누고 마지막 리프 노드가 각기 다른 위험수준을 나타냅니다.
사용 가능한 알고리즘과 소포트웨어
결정 트리 생성에 사용되는 대표적인 알고리즘은
- CART: 분류 및 회귀 트리
- C4.5 / C5.0: 엔트로피 기반 정보이득
- CHAID: 카이제곱 기반 분할 기준
- QUEST: 통계적으로 편향이 적은 분할 방식
결정트리의 장점
- 복잡한 변수 관계 단순화
- 결측값, 왜도, 이상치에 강함
- 해석과 시각화 용이
- 의료 데이터처럼 다양한 변수들이 존재하는 경우 매우 유용
결정트리의 단점
- 소규모 데이터에서 과적합 위험이 큼
- 통계적 관련성은 있어도 인과성은 없음을 유의해야 함
- 입력 변수 간 상관관계가 강한 경우, 불필요한 변수가 선택될 수 있음



